Recently, in the mashups category…
 On Wednesday we went down to Dallas to attend the OnAIR Bus Tour. We were on something of a tour ourselves, having first driven to Graham, TX for a meeting with a potential client, then to Dallas, then home, all in the same day.
On Wednesday we went down to Dallas to attend the OnAIR Bus Tour. We were on something of a tour ourselves, having first driven to Graham, TX for a meeting with a potential client, then to Dallas, then home, all in the same day.
Adobe puts on quite a show. They rented out a movie theater for the day, much to the dismay of all the people who came by wanting to watch a movie. They had plenty of free food, drink, games, etc. It’s pretty cool to walk up to a movie concession counter and have your choice of anything you want, for free.
The sessions were good, too. They walked us through what the Adobe Integrated Runtime is, what you can do with it, and how to get started using it. It’s a pretty interesting runtime. Nobody’s going to decide to build an AIR app instead of a web app, but I can see two scenarios where it would be the way to go:
For web developers/designers who want to use their existing skills to build desktop apps.
For creating widgets to supplement the functionality of an existing site.
And in fact, I’ve already got a few ideas that fall squarely in the second category. I think I’ll play with it and see what I can come up with. Maybe AIR will be useful, maybe it won’t. Regardless, we had a fun (albeit exhausting) evening with the OnAIR folks.
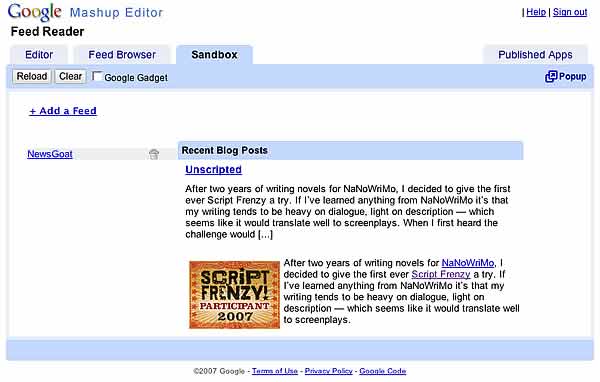
 I received an invitation to the Google Mashup Editor a couple of days ago. I haven’t had time to really play with it yet, but I wanted to give my initial impressions.
I received an invitation to the Google Mashup Editor a couple of days ago. I haven’t had time to really play with it yet, but I wanted to give my initial impressions.
When I first heard about it, I was under the impression it would be similar to Yahoo Pipes. While the idea is similar — primarily, using feeds as data input for building web apps — the implementation is completely different. Where Yahoo Pipes is a visual app builder, Google Mashup Editor is a web-based IDE. It consists of a text editor, feed viewer, and a test environment.
The real meat of GME is the <gm:> tags. You can think of this as a templating language. The tags provide UI controls, data access, control structures, etc. You combine these with basic (X)HTML, CSS, and JavaScript to build your mashup. When you run the application, the tags are “compiled” into standard JavaScript.
Now, here’s the $60,000 question: If the <gm:> tags are simply template tags that turn into JS, why didn’t Google just release it as a library? It seems like it would be simpler — and more useful — to let people download a Google Mashup Library than to build an entire IDE around it and restrict applications to only living on their servers. But maybe that’s coming later.
As I said, I haven’t had much time to play with it yet, but hopefully I will get something built with it soon to really test out what it can do.
 Do you know what your Representative is doing? How about your Senators? I typically don’t, unless they do something embarrassing or are running for re-election. So how can you, concerned citizen, keep up with what your congresscritters are doing?
Do you know what your Representative is doing? How about your Senators? I typically don’t, unless they do something embarrassing or are running for re-election. So how can you, concerned citizen, keep up with what your congresscritters are doing?
I’m glad you let me ask on your behalf!
OpenCongress, which I’ve mentioned before, provides three feeds for each Congress person: voting, news, and blogs. You could simply subscribe to all those individual feeds, but that would get you back to work too quickly. Instead, we’re going to build a Yahoo Pipe that combines these feeds and mangles them in useful ways.
If you’ve never used Yahoo Pipes before you should sign up and play with it a little first, otherwise you will have no idea what I’m talking about here. I also recommend looking at the Pipe I built to understand what’s going on. You could even clone it to make creating your own easier. But, again, think about why we’re doing this to begin with: to avoid real work.
You need to start by looking up your representatives on OpenCongress. If you don’t know who they are, visit here and here to find out, then search for them on OpenCongress.
 Looking at the page for each congress person, you’ll see three orange “Feed” buttons. Copy the locations of those feeds — we’ll need them in a minute.
Looking at the page for each congress person, you’ll see three orange “Feed” buttons. Copy the locations of those feeds — we’ll need them in a minute.
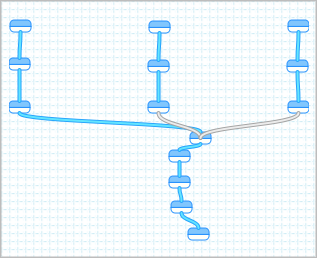
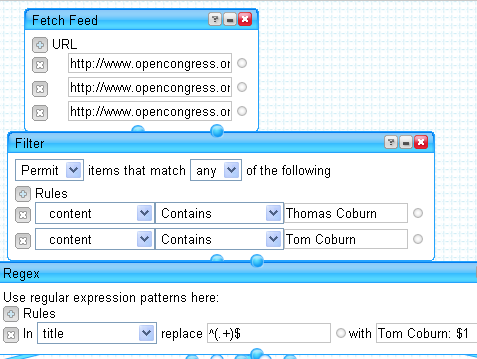 Now, create a new Yahoo Pipe and add the following: 3 Fetch Feed modules, 3 Filter modules, 3 Regex modules, 1 Union module, 2 Unique modules, and a Sort module. In one of the Fetch modules add the three feeds for a particular Congress person. Connect that module to a Filter module. The Filter should be set to “Permit items that match any of the following.” Then add rules like this:
Now, create a new Yahoo Pipe and add the following: 3 Fetch Feed modules, 3 Filter modules, 3 Regex modules, 1 Union module, 2 Unique modules, and a Sort module. In one of the Fetch modules add the three feeds for a particular Congress person. Connect that module to a Filter module. The Filter should be set to “Permit items that match any of the following.” Then add rules like this:
content Contains Thomas Coburn
content Contains Tom Coburn
Why are we doing this? Well, the OpenCongress news and blog feeds are doing “AND” searches on names — basically, looking for any article that has both Thomas and Coburn in it. This is not so much a problem with a name like Coburn, but with Representative Frank Lucas I kept getting news about Frank Smith and Lucas Tyler and all the fish they caught on their last excursion.
In my example above, the second line is probably wasted, but I throw it in anyway just to be complete. If you do something like that, be very sure you set the Filter to match “any”. I forgot to do this on one of mine and couldn’t figure out why I wasn’t getting any items about Senator Inhofe.
Now, link the Filter to a Regex. Your Regex rule should be like this:
In title replace ^(.+)$ with Tom Coburn: $1
We do this so that it’s easy to glance at headlines and know which representative the item is about.
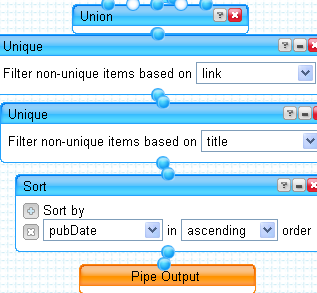 Now, repeat what we just did for each of your other two Congress people. Then connect each Regex module to the Union module. Connect the Union to one of the Uniques and set it to filter based on link. This will remove any article that shows up twice, perhaps because it had two or more of your representatives mentioned. Connect this Unique module to another Unique module and set the second one to filter on title. This will remove some (but not all) instances where an AP article shows up on multiple sites. Attach the second Unique to the Sort module and sort on pubDate. Finally, connect the Sort to the Pipe Output and you’re done.
Now, repeat what we just did for each of your other two Congress people. Then connect each Regex module to the Union module. Connect the Union to one of the Uniques and set it to filter based on link. This will remove any article that shows up twice, perhaps because it had two or more of your representatives mentioned. Connect this Unique module to another Unique module and set the second one to filter on title. This will remove some (but not all) instances where an AP article shows up on multiple sites. Attach the second Unique to the Sort module and sort on pubDate. Finally, connect the Sort to the Pipe Output and you’re done.
And see? Now’s it’s almost time to start your weekend. Want the procrastination to last a little longer? Blog about it!
I wish I could create a Pipe that would allow people to input something (name, ID, etc.) and get a feed just for them. OpenCongress assigns unique IDs to each Congress person, but their feeds contain both the ID and the name, and all the string manipulation required to deal with names would be problematic.
If you do create your own Elected Representatives Pipe, I encourage you to Publish it and either leave a comment here or blog about it on your own site. That way, other people in your district can find it and make use of it. Who knows? If people start paying attention to what Congress is doing, all kinds of interesting things could happen.
As I started thinking about an election Pipe, I had this grand vision of an uber-feed that would pull together news, blog, and Congressional voting (when applicable) information on all candidates into a political information overload.
That didn’t so much pan out. Apparently, there is a limit to the number of feeds — or possibly feed items — that Yahoo Pipes can handle. Somewhere around 12, 13 feeds the Pipe got clogged and wouldn’t return any results. And since that was less than half of the list of feeds I had, I decided to scale things way back.
So I created the 2008 Presidential Candidates, Congressional Votes Pipe. As far as Pipes go, it’s as simple as it gets — it just pulls the voting record feed from OpenCongress.org for each Congressperson that is running for President. It seemed useful to see how the candidates are voting (or if they’re voting) in the months before the election. And if you want blogs and news there are plenty of Pipes that provide that.
I’ll do my best to keep it updated as people drop in and out of the race.
I don’t know about you, but I have far more artists in my music library than I can keep track of. Every once in a while I’ll be listening to a song and think, “I wonder if they have anything new out.” Then I look and find I’m two or three albums behind. When I heard about Last.fm and their data feeds I thought there should be a way to use that. Then when Yahoo Pipes came out, I knew there was. So over the last couple of days I spent my free time throwing together my New Releases Pipe.
New Releases takes the artists from your Last.fm recent tracks feed and searches for them in iTunes New Releases feed. The hardest part was wrapping my head around the “For Each” operators in Yahoo Pipes. What I wanted to do was filter one feed using text from another feed. “For Each” is how you do that. You have to create another pipe (in this case, Find New Releases) that does a search of the feed based on a text input. When you drop that Pipe into the “For Each” module, you can link that text input to a data field coming from the other feed.
Now, some caveats:
Searching based on an exact text match always, always, makes me nervous. This really depends on Last.fm and iTunes using the exact same name for the artist — spaces, punctuation, everything. Because of that, expect this to miss some things.
This is really hit or miss, anyway, because it’s matching your last 10 tracks from last.fm to iTunes 100 new releases. To improve your odds of finding albums, set your feed reader to update fairly often (probably an hour, although every 30 minutes would be ideal) and listen to music constantly.
To get the artist name from the Last.fm feed with the least amount of trouble I’m running regular expressions against the artist URL in the description field. This requires, among other things, replacing all the plus signs with spaces. Yahoo Pipes doesn’t have a “replace all” function yet, so I’m just replacing one plus sign several times to try to catch them all. Because of this, you might miss releases from “…And You Will Know Us By The Trail Of The Dead.” You’re welcome.
Anyway, try it out, and if you have recommendations for improvements post them in the comments. I have some ideas of my own, and I will be posting them when they’re done.